

How to Implement Respondent-Driven Sampling in Practice: Insights from Surveying 24-Hour Migrant Home Care Workers
Hipp L., Kohler U. & Leumann, S. (2019). How to Implement Respondent-Driven Sampling in Practice: Insights from Surveying 24-Hour Migrant Home Care Workers. Survey Methods: Insights from the Field. Retrieved from https://surveyinsights.org/?p=12000
© the authors 2019. This work is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0) 
Abstract
This article draws on the experience from an ongoing research project employing respondent-driven sampling (RDS) to survey (illicit) 24-hour home care workers. We highlight issues around the preparatory work and the fielding of the survey to provide researchers with useful insights on how to implement RDS when surveying populations for which the method has not yet been used. We conclude the article with ethical considerations that occur when employing RDS.
Keywords
hidden populations, illicit behaviours, practical implementation, respondent-driven sampling
Acknowledgement
This research was funded by a grant from the German Ministry of Labour and Social Affairs (Fördernetzwerk Interdisziplinärer Sozialpolitikforschung (FIS) “Wer kümmert sich um Oma? Eine empirische Erprobung des Respondent-Driven Sampling am Beispiel der (informellen) Beschäftigung in der häuslichen Pflege“). We would like to thank our student assistants, Pawel Binczyk, Martyna Dach, Jan Eilrich, Katharina Köhler, Michał Łuszczyński, Valerie Stroh, and Joanna Trzaskowska, for their help with the data collection. We are also grateful to Britta Jurtz and Adam Reiner for their help implementing the survey (and its audio version) in Lime Survey. We are indebted to Nadia Zeissig and Gabriela Kapfer (University of the Arts, Berlin) for their help in designing the coupons and producing the informational video, as well as to Dr. Patrycja Kniejska, Prof. Dr. Helene Ignatzi, Monika Firjarczyk, and Dr. Sylwia Timm for sharing their valuable insights into the lives of migrant home care workers. Last but not least, we thank Prof. Dr. Barbara Städtler-Mach, Prof. Dr. Arne Petermann, Michael Gomola and Dr. Jonas Hagedorn for their help in accessing the field, and the Berlin public libraries for providing us with survey space.
Copyright
© the authors 2019. This work is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0)
Introduction
Public interest in demographic groups that are small, hidden, mobile, or engaged in illicit activities has grown in recent years. Examples of such hard-to-reach populations include drug addicts, prostitutes, migrants, the homeless, and the very rich. Yet, commonly used probability sampling designs cannot be applied to these groups for a variety of reasons, including the absence of sampling frames, the small size of the group in question relative to the overall population, frequent changes of address, and reluctance to participate.
Respondent-driven sampling (RDS) is one method that can be used to reach these populations. It is a network-based sampling method that starts with a convenience sample and incentivises respondents not only to participate in the survey themselves but also to get their contacts from the target population to participate. Participants receive coupons with unique identification numbers for themselves as well as their recruits. Drawing on Markov chain theory, researchers use the respondent’s network size and composition to estimate selection probabilities for each sampled unit. This in turn allows them to produce acceptable (point) estimates for the study population (see Gile et al. 2018; Heckathorn & Cameron 2017). Under a given set of assumptions, the final sample of an RDS design is independent of the characteristics of the initial respondents and shares properties of a probability sample (Heckathorn 2002; see Lee et al. 2017 for a critical review on the RDS assumptions). The generated data can be used for calculating point estimates and descriptive group comparisons but not (yet) for uncertainty estimates or any type of inference statistics (ibid.).
To date, RDS has been employed primarily in the public health sector to detect HIV infections in drug addicts and prostitutes (e.g., Heckathorn et al. 2002 and Decker et al. 2014). Other groups to whom it has been applied include homeless people (Dávid & Snijders 2002) and migrants (e.g., Friberg et al. 2014; Montealegre et al. 2013 ) as well as jazz musicians (Heckathorn & Jeffri 2001).
Thanks to the increasing use of the method, useful and practical information about RDS implementation has recently been made available (for example by the World Health Organisation (WHO) 2013) However, when applying RDS to populations that have not previously been surveyed using this method, researchers encounter questions and challenges arise with regard to implementation. These include difficulties with recruiting of the initial respondents, interview location, incentive structure, and many more.
This article therefore provides practical insights from an ongoing research project, in which we use RDS to survey a demographic group with whom RDS had not previously been used: 24-hour migrant home care workers. This group consists of people who do not live permanently in Germany and who care for sick and elderly persons on a 24-hour basis for pay, for example, because those persons suffer from dementia or are physically disabled; they therefore presumably live in the same (or at least close to the) household of the person they care for.
Twenty-four-hour migrant home care workers are an almost “ideal” target group with whom to use RDS. First, they are a highly relevant group that have not been studied quantitatively so far (see for example, Deutscher Bundestag 2018, 2019). Second, they are difficult to reach. Despite the increase in the number of people in need of sick and elderly care, 24-hour care workers are a comparatively small group within the overall population. Moreover, in light of the regulations currently in place in Germany governing working hours and pay, at least some of these 24-hour care workers presumably work illicitly, and those in our study move frequently. Third, the group of 24-hour home care workers from Poland who work in Germany seem to be a relatively tight-knit community (Kniejska 2016).
Using Respondent-Driven Sampling to Survey (Illicit) Home Care Workers
Study design and setting: 24-hour home care workers from Poland in Berlin
The present study intended to estimate the prevalence of (illicit) 24-hour migrant home care workers and to learn more about their working and living conditions. Where do these workers come from? Why do they choose to work as home care workers? What tasks do they perform? Answering these and related questions is particularly important in light of the rising average age of the German population, which will likely further increase the demand for home care services in the future. Employment in the home care sector is generally characterized by a high level of precariousness, very low incomes, and poor working conditions, as reported in a number of qualitative case studies (e.g., Emunds & Schacher 2012; Karakayali 2010). These studies, along with a number of journalistic accounts, suggest a wide range of illegal and semi-legal practices in the sector (Martiny & Stolterfoht 2013). According to estimates by the German Professional Association for Nursing Professions, between 100,000 and 800,000 nursing assistants currently work illegally in German private households (ZQP 2016), while the number of legally employed workers in outpatient care services is only 356, 000 (Federal Statistical Office 2017).
Key features of RDS
Respondent-driven sampling (RDS) has been developed as a method to survey populations that are difficult to reach because they are small, hidden, or mobile, or because members of the target population are not interested in participating in the survey—for example, because they are engaged in socially undesirable behaviours. Standard probability sampling methods are of limited use when seeking to learn more about these populations. For instance, when surveying individuals who report that they work in elderly care in national probability surveys, we would probably miss home care workers without formal training in elderly care and those who are working in Germany illegally. The sample would hence most likely not resemble the population in terms of its relevant characteristics. Other sampling procedures, such as snowballing and other network-based methods, run into the problem of biasing survey participation and hence do not allow researchers to make statistically sound inferences about the target population. The introduction of RDS resolved this dilemma of choosing between different types of sampling biases (Heckathorn 1997).
Put simply, RDS combines elements of snowball sampling and network analysis to achieve high statistical validity in samples that were collected using nonrandom procedures. Starting with an initial convenience sample (“seeds”), researchers incentivise respondents to recruit their peers to also participate in the survey. By keeping track of the respondents’ social networks and recruiting patterns, researchers can applying mathematical models of the recruitment process using Markov chains and biased network theory and weight the sample to compensate for the initial non-randomness of the seeds. When correctly applied, RDS can provide population estimates of the target population that are only modestly biased (Heckathorn 1997).
Formative assessment
As part of our preparatory work, we studied the previous research on home care work and conducted focus-group interviews with researchers and practitioners with expertise in the field. Spending time on this “formative assessment” phase helped us a great deal in gaining important insights into our target population and in answering the questions that researchers employing RDS should typically ask themselves (Johnston et al. 2010; WHO 2013). Is the population socially networked? Are there subpopulations? How should we choose our seeds? What are appropriate survey locations? How can members of the target population best be incentivised? What are the subject areas that should potentially be covered in the survey?
Identifying the target population
When applying for the grant funding for our survey, we intended to learn about the entire population of migrant home care workers in a specified local area. Our formative assessment, however, soon revealed that such a broad approach would not be feasible. The different subpopulations of migrant home care workers appeared to be isolated from one another and often only have limited German language skills. This lack of German language skills had various implications: it imposed practical constraints on our attempt to study migrant home-care workers from different countries, but it also meant that that an equilibrium would be hard to reach if the different groups of home-care workers were separated by language barriers (see Heckathon 1997: 192). We therefore decided to limit our target population to live-in care workers from Poland, who seem to be the biggest group of care workers in the region in which we conducted our research.
Selecting the interview site
Our discussion with researchers, trade unionists, and social workers revealed several aspects relevant for selecting an appropriate interview site. Twenty-four-hour live-in care workers do not seem to be evenly distributed throughout the city but tend to live in affluent neighbourhoods that are not well connected to public transportation. Moreover, as live-in care workers appear to have limited free time available, we nonetheless had to decide on an interview location that would be easy for them to reach in order to keep the threshold for participation in the survey as low as possible. A third consideration that guided our choice of interview location was the general sense of mistrust toward government institutions in our target population, as reported in interviews carried out as part of our formative assessment. Some of our initial ideas for meeting these requirements, such as using a modified construction trailer to conduct the interviews in different neighbourhoods or using signal towers at local train stations, did not prove to be viable solutions. They were either too costly or the administrative barriers to implementation were too high. Instead, we opted for rooms in two public libraries that we assumed to be conveniently located for care workers in two parts of the city, and ensured that our opening hours were compatible with what we assumed their schedules to be. We also offered to interview workers at a different place of their choice if they preferred. This, of course, increases the costs per interview and had to be budgeted for beforehand.
More preparatory work
Sample size calculations and incentives
The main purpose of our research project was to estimate the prevalence of certain characteristics in 24-hour home care workers from Poland, including the number of hours they worked on an informal basis. The number of observations theoretically needed for this can be calculated with
![\[ n = \text{Deff} \cdot \frac{z_{1 - \alpha}^{2} \cdot \text{Var}(Y)}{\omega^{2}} \]](https://surveyinsights.org/wp-content/uploads/ql-cache/quicklatex.com-8962c7b87e3c44247bf1dac03dae15a2_l3.png "Rendered by QuickLaTeX.com")
where  is Kish’s design effect (Kish 1965),
is Kish’s design effect (Kish 1965),  is the critical value of the normal distribution for the confidence level
is the critical value of the normal distribution for the confidence level  (1.96 for the common 5\% -level),
(1.96 for the common 5\% -level),  is the variance of “the” variable under study, and
is the variance of “the” variable under study, and  is the acceptable width of the confidence interval. In order to apply this formula to our case we first had to set the unknown parameters and . In order to have sufficient numbers of observations for all situations, we decided to choose the highest possible variance for a dichotomous characteristic for . As the variance of a dichotomous characteristic is
is the acceptable width of the confidence interval. In order to apply this formula to our case we first had to set the unknown parameters and . In order to have sufficient numbers of observations for all situations, we decided to choose the highest possible variance for a dichotomous characteristic for . As the variance of a dichotomous characteristic is  , with
, with  being the proportion of “successes” for the dichotomous characteristics, the maximum variance is
being the proportion of “successes” for the dichotomous characteristics, the maximum variance is  . For the unknown parameter we followed the majority of RDS samples by setting
. For the unknown parameter we followed the majority of RDS samples by setting  (WHO 2013: 51). This means that we strived for a sample size two times the size of a simple random sample. It should be noted, though, that some analyses of RDS data indicate that design effects should be much larger, possibly as large as
(WHO 2013: 51). This means that we strived for a sample size two times the size of a simple random sample. It should be noted, though, that some analyses of RDS data indicate that design effects should be much larger, possibly as large as  (see Salganik 2006). Generally, the more similar respondents recruited by one seed are to respondents from other seeds, the larger
(see Salganik 2006). Generally, the more similar respondents recruited by one seed are to respondents from other seeds, the larger  should be. Finally we set to the common 5\% level and stipulated the acceptable width of the confidence interval to be +/- 2.5\%, leading to
should be. Finally we set to the common 5\% level and stipulated the acceptable width of the confidence interval to be +/- 2.5\%, leading to  .
.
Using the settings just described, we initially arrived at a target sample size of
![\[ n = 2 \cdot \frac{{1.96}^{2} \cdot 0.25}{{0.05}^{2}} = 768 \]](https://surveyinsights.org/wp-content/uploads/ql-cache/quicklatex.com-c1638e6195e0ac1d5f5ade1cf79005f2_l3.png "Rendered by QuickLaTeX.com")
observations.
However, in the course of our research project, we had to modify the target sample size due to some very practical restrictions that other research teams may also encounter. The total sum of funds available to pay the incentives for our target population was around 20,000 euros. As respondents in RDS are rewarded for their participation in the interview and for referring additional respondents, our initial attempt at interviewing almost 800 persons therefore left us with a total of 25 euros for incentives per interview on average (15 euros for the actual interview and 10 euros for the referral). Based on the insights generated during the formative assessment, this seemed a reasonable choice.
When seeking to recruit the seeds for our project, however, these settings turned out to be overly optimistic. It was impossible to identify individuals who were willing to be interviewed, although we offered to conduct the interview anywhere that was convenient for them (in addition to our two interview locations in areas where 24-hour home care workers were most likely to be located, as we had learned in the formative assessment). Ultimately, we therefore had to increase our primary incentives to 40 euros per interview, and we paid respondents 8 additional euros for each successful referral of up to four further interviewees. At the same time, we had to reduce the target sample size to 400 respondents, which corresponds to an acceptable width of the confidence interval of +/- 0.35% for an evenly distributed dichotomous characteristic.
Seeds and Number of Coupons
RDS requires an early decision about the number of seeds and the maximum number of coupons every respondent receives. Concerning seeds, practices in existing RDS studies vary widely between 2 and 32 seeds, with an average of 10 (WHO 2013: 70). It should be kept in mind that it is preferable to reach the target sample size through long chains of a few seeds as opposed to short chains of many seeds. The following formula provides a rough estimate for the predicted sample size under various conditions:
![\[ \hat{n}_{W,s,c,r,p} = \sum_{}^{}p \cdot s \cdot (c \cdot r)^{w - 1} \]](https://surveyinsights.org/wp-content/uploads/ql-cache/quicklatex.com-7a4e7681283233736ff5cd6141e54e12_l3.png "Rendered by QuickLaTeX.com")
with being the proportion of recruited seeds that actually participate,  being the number of seeds recruited,
being the number of seeds recruited,  being the number of coupons every respondent receives, r being the response rate of the recruits, and
being the number of coupons every respondent receives, r being the response rate of the recruits, and  being the recruiting waves. For example, if an RDS sample uses
being the recruiting waves. For example, if an RDS sample uses  seeds of which
seeds of which  actually come to an interview, and each respondent (including the seeds) receives
actually come to an interview, and each respondent (including the seeds) receives  coupons for recruiting other respondents, of which
coupons for recruiting other respondents, of which  come to an interview, the predicted sample size after four recruiting waves would be
come to an interview, the predicted sample size after four recruiting waves would be
![\[ n_{4,5,3,0.8,0.66} = 4 \cdot 2^{0} + 4 \cdot 2^{1} + 4 \cdot 2^{2} + 4 \cdot 2^{3} = 60 \]](https://surveyinsights.org/wp-content/uploads/ql-cache/quicklatex.com-9a197ab69e10dfb51c952a74f72210ef_l3.png "Rendered by QuickLaTeX.com")
In practice, the average response rate of seeds is (WHO 2013: 70). Figure 1 therefore shows the results of equation (2) for various settings of the other quantities that affect the predicted sample size. The figure shows that an RDS design with just two coupons will not reach high sample sizes even after 10 recruitment rounds. Using five coupons, on the other hand, bears the risk of reaching the sample size too early. Hence, RDS designs should use five coupons only if low response rates of potential recruits are expected.
Figure 1: Expected sample sizes by number of recruited seeds, number of participating seeds, number of coupons, and number of recruitment waves
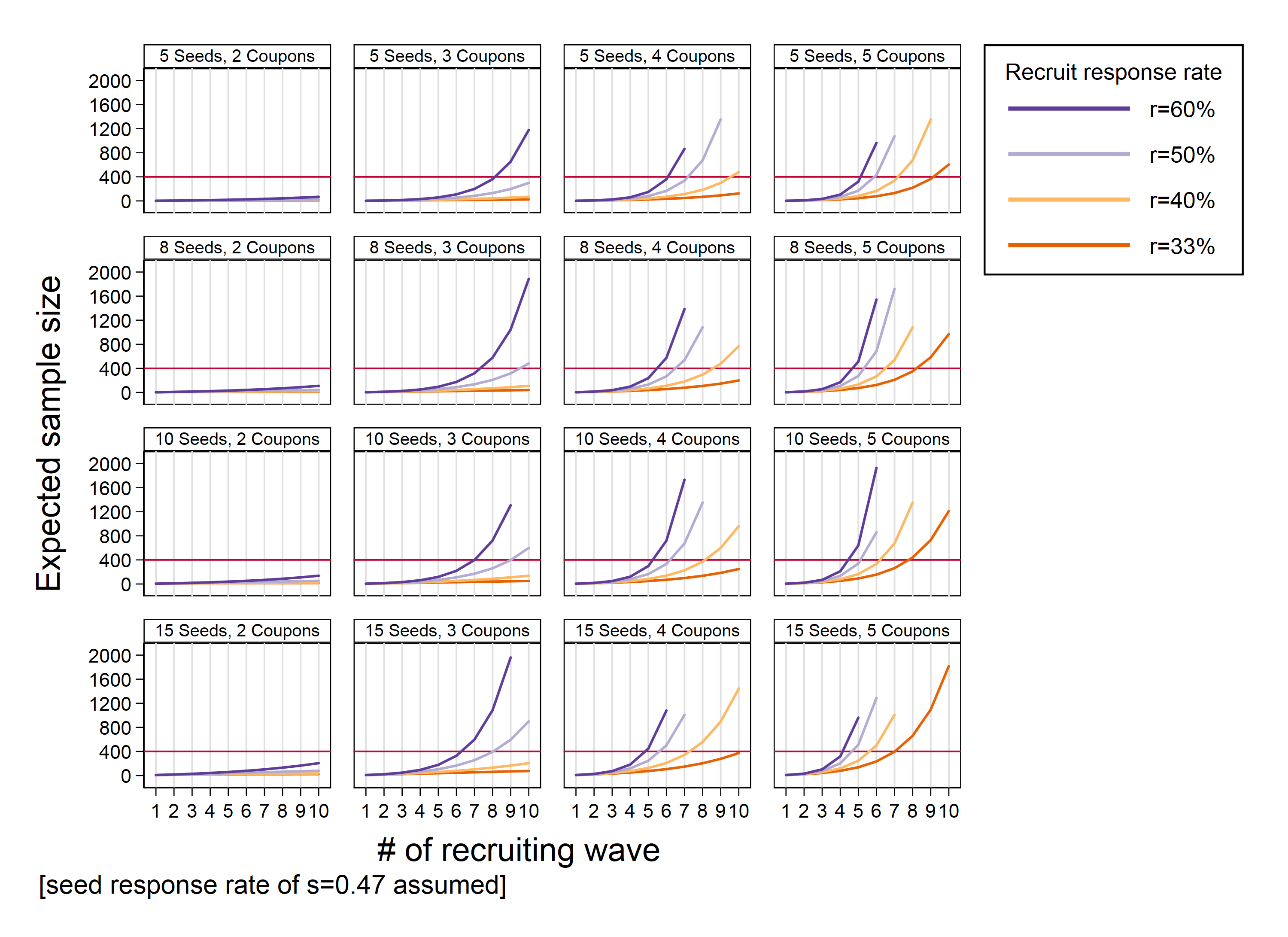
Note: The figure was created with the Stata do-file SMIF_figN.do, which can be found in the supplementary material section; readers may adapt it to the context of their own project.
Designing the coupons
In its manual about the use of RDS in detecting HIV infections, the World Health Organization (2013) recommends that coupons should provide the information necessary for respondents to participate in the survey, should be easy to track without being easily reproducible, should contain the information needed to link the interviewee with his or her recruiters and recruits, and should have an attractive appearance indicating its value. To ensure that the coupons were not easily reproducible, we printed them on thick, colored paper. Moreover, by stamping the coupon numbers on the coupons instead of writing the coupon numbers by hand, we further increased the difficulty of reproducing the coupons and sought to minimize errors.
Our coupon consisted of two parts. One part of the coupon, which we printed on red paper, was meant for the interviewee to keep (i.e., the “coupon receipt”), and the other part, which was printed out on blue paper, was the coupon that the respondent could give to his or her recruits (i.e., the “handout coupon”). He or she received up to four of these blue coupons. All information on the coupons was provided in Polish and was supplemented, whenever possible, with icons.
Figure 2 shows the coupon receipt, which contained the respondent’s coupon number and the initials of the persons who the respondent recruited for further participation in the survey, along with their coupon numbers. With these numbers, interviewees were given the possibility to check on our project website to see how many of their recruits had already appeared for an interview.
Figure 2: Stylized Design of the “Coupon Receipt”


Figure 3 shows one of the blue coupons for the further recruits, which contained all the necessary information about the drop-in hours, the survey sites, the procedures, and the duration of the interviews, along with our contact information, information about compensation, and where participants could go to learn more about the project.
Figure 3: Stylized Design of the “Handout Coupon”

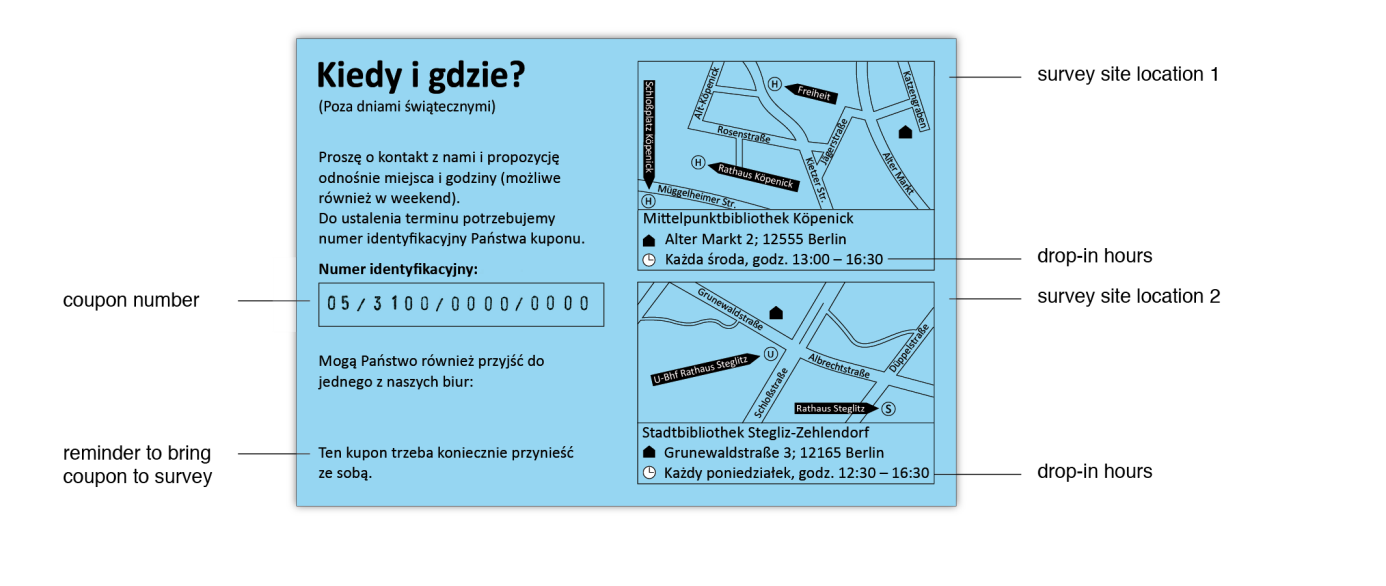

Several considerations guided the design of our coupons. First, we did not want the coupons to look commercial or “too” official, but still wanted them to make a professional impression. Ultimately, we wanted to design the coupon to look like an invitation, with all the necessary information presented clearly. We chose a rounded, sans serif font to ensure readability and give it a somewhat informal appearance. The coupons also included our logo to boost recognition of and trust in the project, as the logo was also used on signs pointing the way to our interview locations, in an informational video, and on our website. Second, we wanted to ensure that the coupons would fit into respondents’ purses or wallets so that they could carry them with them and hand them out to others. We therefore opted to print them at approximately the size of a credit card.
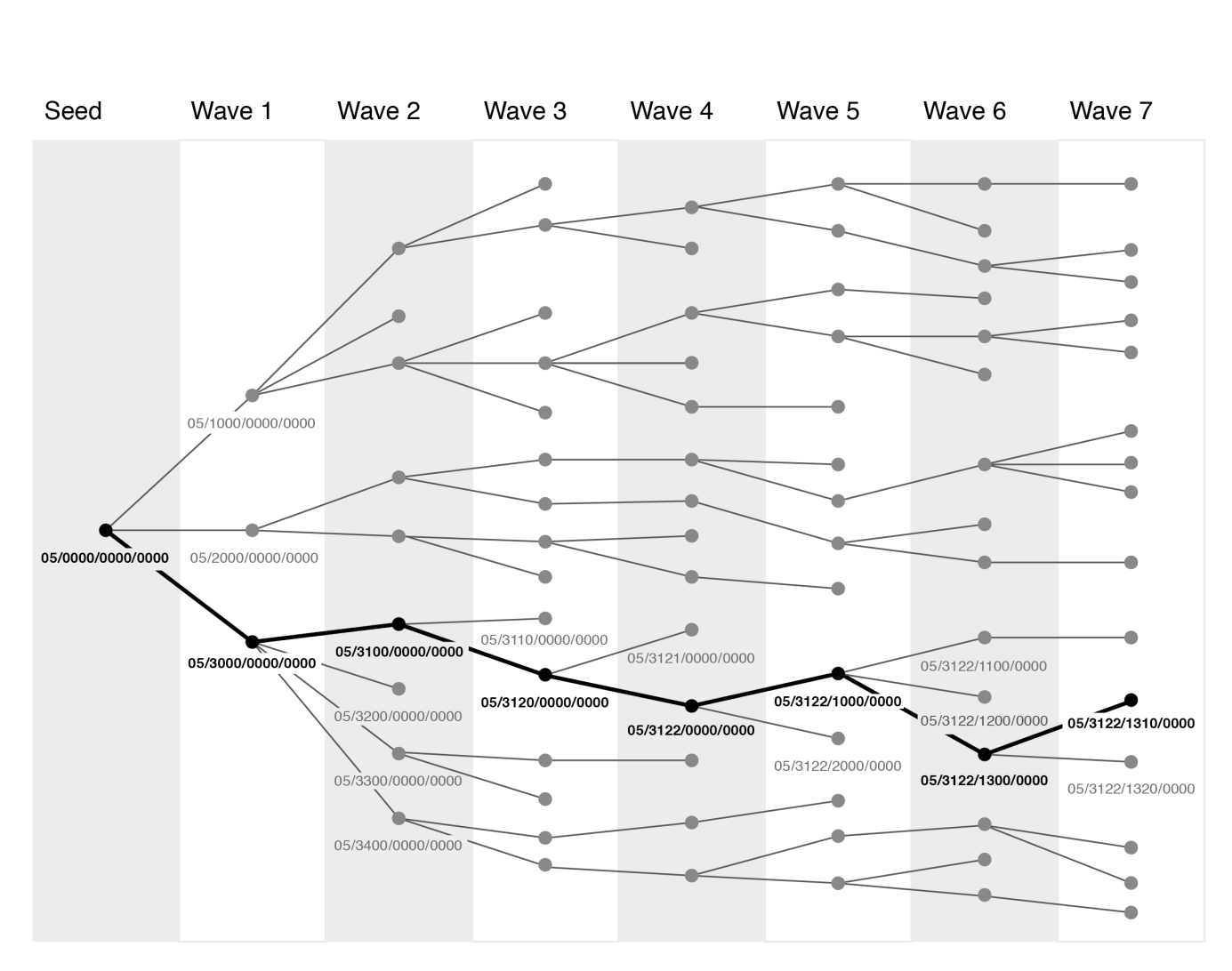
In order to minimize the bias of RDS estimators, researchers need to know the size of respondents’ networks in the target population and be able to link respondents’ information to the information on their recruiters and recruits. These pieces of information are a precondition for RDS analysis (Heckathorn 1997). We therefore chose a sequential numbering system (see Figure 4). Each respondent was assigned a unique 14-digit number on his or her coupon. The first two digits provided the information about the seed who had initiated the respondent’s referral chain. The next digit provides the information about the coupon through which the respondent had been recruited. The following digits provide the information about the further recruitment pathway of a particular respondent. For example, the coupon number “05/3100/0000” tells us that the respondent was recruited by our fifth seed, using the seed’s third coupon. The four coupons that this particular respondent had to distribute were numbered as follows: “05/3110/0000”, “05/3120/0000”, “05/3130/0000”, “05/3140/0000”. The respondent who was recruited with the coupon numbered “05/3130/0000”, in turn, received up to four coupons with the numbers “05/3131/0000”, “05/3132/0000”, “05/3133/0000”, “05/3134/0000”, which she or he further distributed within his or her network. This numbering system allowed us to clearly identify the respondents without needing to know their names, while always knowing about the length of the referral chain. To avoid errors regarding the generation of the coupon numbers and to ensure that the numbers on the coupon and the respective coupon receipt match, we used a stamp instead of handwriting the numbers. As even this procedure cannot eliminate the possibility of errors, we took pictures of all the coupons and coupon receipts, which we kept for our records as an additional control mechanism.
Figure 4: Stylized Recruitment Chains with Numbering Scheme
Fielding the survey
Recruiting seeds
One challenge that we had not originally anticipated was the recruitment of our seeds. On the one hand, this had to do with our incentive, and on the other, with our recruiting strategy. In contrast to prostitutes or drug addicts, who were incentivised in past studies not only through financial reimbursement for participation and referral of additional study participants, but also through the provision of health screenings and services (WHO 2013), no such targeted incentive was possible with our study population. We therefore decided to incentivise our respondents by offering 15 euros for their participation in the interview (i.e., the primary incentive) and 10 euros for each successful referral (i.e., the secondary incentive). Although primary and secondary incentives could be as large as 55 euros per respondent, this amount – particularly the payment for the primary incentive – turned out to be too low to motivate individuals from our target population to participate in the interview. Only when we increased the primary incentive to 40 euros could we motivate them to participate in our study. To contain costs and to not unnecessarily reduce the total sample size further, we had to reduce the secondary incentive to 8 euros per referral when increasing the primary incentive; this (small) reduction did not seem to negatively influence survey participation.
We also had to become more creative when recruiting our seeds after having initially failed to interview a single person during the first month of our fieldwork. The reliance on intermediaries, such as churches, information centres, or welfare associations, all of which had contact with 24-hour home care workers from Poland, proved ineffective. Eventually, it was personal contacts and a newspaper advertisement that helped us to get the survey started. Recruiting seeds through different pathways increases the diversity of the initial sample, minimizes the risk of breaks in the referral chains, and ensures that network capacities are not exhausted too early and that the central RDS assumption about the final sample being independent of the initial sample holds.
Survey mode
Due to the fact that our target population did not necessarily speak German, and as some of our survey questions touched on sensitive issues, we decided to use a self-administered web-based survey in Polish with supplementary audio files. Respondents could complete the survey themselves in a private area after having answered the network questions. With the audio files, we sought to encourage participation and promote an accurate understanding of the questions, which may either be jeopardized by fast reading of the questions (as it has been the case in our pre-tests) or limited reading skills (which we were not sure our respondents all had). The network questions, which respondents had to answer before filling out the survey, were administered face-to-face by research assistants who spoke Polish as their native language. This initial contact in Polish also helped us to ensure that our respondents indeed came from Poland. It was not possible, however, to make further inquiries or checks to ensure that they actually belonged to our target population. Research assistants were trained, however, to note any behaviors or characteristics that might indicate that interviewees might not actually be members of the target population.
Surveying respondents
To collect respondents’ network information and to potentially also screen out individuals who were not members of the target population, we asked the following questions and provided respondents with a piece of paper so that they could write down the initials of people who fit each of the following criteria: People who a) work in 24-hour home care jobs like themselves, b) come from Poland, c) work in Berlin, d) who they have met with personally in the last two months.
Of those in the respondent’s list who fulfilled all of the criteria, we randomly selected a total of four individuals using a random number generator [https://www.random.org]. We only did so, however, after asking the participant if, to his or her knowledge, any of those listed had already participated in the interview. If they had, we took them off the list, and sampled from the smaller network. The initials of these four individuals were stamped on the respondent’s coupon receipt.
Ethical considerations and challenges with RDS
As is the case with any other research, RDS involves several ethical challenges, including respondents’ assessment of risks and benefits, informed consent, or selection of study participants. Specific to this study were the researchers’ legal and moral dilemmas with regard to learning about illegal behaviour on the part of respondents (DeJong et al. 2009; US Department of Health 2014; Semaan et al. 2009). In collaboration with our Ethical Review Board at our institution, we sought to address these issues by adhering to ethical principles governing human subject research (US Department of Health 2014).
Protecting privacy and minimizing risks for participants
Our study entailed several risks for those who participate. First, by participating and talking about their work, 24-hour home care workers might indirectly reveal information about third parties, in particular, the person they care for, who may be ill or suffering from dementia and did not agree to participate in the study. Second, by participating in our study, respondents could disclose illegal behaviours. This might be a reason why individuals would choose not to participate in the study. Researchers might also be reluctant to report the legal misconduct of individuals who placed trust in them or may not want to condone continued illegal and potentially harmful behaviour. To overcome these challenges, we did not collect any information (e.g., names) that would have made the participants identifiable. While not collecting names or other identifiable information is standard in most other survey types (and therefore usually not deserving of mention), the lack of such information is a challenge when employing RDS, which requires the researcher to collect information on individual networks. We sought to minimize the risk of individuals participating multiple times in the survey by assigning numbers to respondents (see above), and additionally by a) explicitly asking respondents whether they or any of their acquaintances had already participated and b) working with a small team of individuals to collect the data. These procedures also helped us to convince the funding agencies that we would be able to pay the incentives on an anonymous basis.
Moreover, we did not conduct interviews in the households in which our study participants worked (without explicit consent of the employer) to ensure that they did not get into trouble with the person they were caring for, with relatives of that person, or with their employer in cases in which they were not directly employed by the household in which they worked.
Informed consent
Obtaining informed consent in studies employing RDS is relatively easy. Apart from the seeds, study participants in RDS actively signal their willingness by appearing at the interview site or by contacting the researcher by phone. They are usually familiar with the content of the project from the people who recruited them. The fact that participants actively approach the researchers to participate in the interview is a strong indication of consent. However, to ensure that participants were indeed well-informed about potential risks and benefits, we provided them with information about the study and the procedures both in person before they completed the survey as well as on our project website. Moreover, participants were informed that they had the option to not answer particular survey questions, to break off the survey at any time, and to withdraw consent for us to analyze their data with no negative consequences (i.e., without having to return their primary or secondary incentives).
Being truthful and avoiding deception
As our research was funded by the German Ministry of Labour and Social Affairs, which has a vested interest in reducing illicit work and eliminating shadow employment practices, we were afraid that mentioning the ministry would frighten potential participants and thereby reduce participation. However, we also did not want to be untruthful or deceive participants by not telling them who was funding the project or by only telling them after they had completed the survey. We therefore decided to mention in the consent form that the study was funded through a public program and to give the name of the program but did not mention the ministry by name. All research assistants involved in the data collection, however, were instructed that they should give respondents the full name of the agency if there were further questions on this issue.
Selection of Subjects
By attempting to start the sampling procedure with seeds that were as different as possible from one another, we sought to not only optimize the implementation of RDS but also to maximize the diversity of the potential participants and to hence ensure a fair chance of participation among all potential participants. Individuals who chose to be interviewed and had a coupon for participation but were not part of the target population (and were therefore given the coupon mistakenly) were paid the primary incentive for participating in the interview but not included in the data analysis, and did not receive coupons to hand out to other individuals. They hence also did not receive secondary incentives.
Conclusion
In this article, we shared insights from an ongoing study in which we used RDS to survey 24-hour home care workers from Poland. Surveying this population proved to be particularly challenging. It took us around 12 months of preparation before fielding the survey and we had a hard time to recruit seeds. As the study has not yet been completed at the time of writing, we can unfortunately not report on any substantive findings from this research. We can, however, provide some descriptive information on participants, interview duration etc. and can refer interested readers to our project websites (https://wzb.eu/en/rds), where all reports and articles coming out of this project will be published. At the time of submission of this article, we had conducted interviews with 89 individuals (out of which 90% were female); these were generated by 4 seeds and formed 43 chains of an average length of five referrals (with the maximum chain length being nine). The average interview duration was a little less than 40 minutes, including the average of three minutes for asking network questions. However, the total time participants spent with the Polish interviewers tended to be much longer as they liked to talk about their work before starting and after finishing the self-administered questionnaire.
Based on our experience, we believe that researchers using RDS in their work can benefit from the main lessons we learned. First, when relatively little is known about the target population, and when that population is heterogeneous, researchers are well advised to spend adequate time on formative assessment. In our case, expert interviews and a thorough study of qualitative work on migrant home care workers helped us to delineate our target population to 24-hour live-in care workers from Poland. These interviews also helped us to identify locations in the parts of the city where our target population could be expected to work and that would potentially be valuable sites for recruiting the seeds.
Second, RDS may fail to produce reliable results if recruitment chains are too short or if costs skyrocket due to excessively high numbers of participants early on. It is therefore crucially important to decide on the number of coupons to be handed out to the recruits.
Third, the coupons employed in RDS designs must be designed so that they convey the necessary amount of information within limited space while having an appealing appearance and being difficult to copy. The expiration date on the coupons, moreover, needs to be carefully chosen to ensure that interview chains are long enough but that costs do not exceed budget.
Fourth, in the course of implementing the survey, we realized that despite the initial impression that 24-hour migrant home care workers are an ideal population for RDS, surveying this population is actually quite challenging. Our initial incentives were not high enough. Moreover, 24-hour care workers have very limited time, which also makes it difficult to interview them. Moreover, it was almost impossible to recruit seeds in our target population without intermediaries.
Fifth, employing RDS also turned out to be more costly than anticipated, as we had to spend additional resources on technical equipment, professional translations, and had to pay higher primary incentives to foster participation. In addition to careful cost calculations, researchers should invest in strong network and supportive cooperation partners who may help them to contain costs (e.g., by providing target-population-specific incentives).
References
- Dávid, B. and Snijders, T.A. (2002) Estimating the size of the homeless population in Budapest, Hungary, Quality and Quantity, 36, 3, 291-303.
- Decker, M.R., Marshall, B.D., Emerson, M., Kalamar, A., Covarrubias, L., Astone, N., Wang, Z., Gao, E., Mashimbye, L. and Delany-Moretlwe, S. (2014) Respondent-driven sampling for an adolescent health study in vulnerable urban settings: a multi-country study, Journal of Adolescent Health, 55, 6, S6-S12.
- DeJong, J., Mahfoud, Z., Khoury, D., Barbir, F. and Afifi, R.A. (2009) Ethical considerations in HIV/AIDS biobehavioral surveys that use respondent-driven sampling: illustrations from Lebanon, American Journal of Public Health, 99, 9, 1562-1567.
- Deutscher Bundestag (2018) Arbeitsbedingungen von im Haushalt lebenden Pflegekräften. Kleine Anfrage der Abgeordneten Pia Zimmermann, Susanne Ferschl, Matthias W. Birkwald, Sylvia Gabelmann, Dr. Achim Kessler, Katja Kipping, Jutta Krellmann, Pascal Meiser, Cornelia Möhring, Jessica Tatti, Harald Weinberg, Sabine Zimmermann (Zwickau) und der Fraktion DIE LINKE. Drucksache 19/6392.
- Deutscher Bundestag (2019) Arbeitsbedingungen von im Haushalt lebenden Pflegekräften. Antwort der Bundesregierung auf die Kleine Anfrage der Abgeordneten Pia Zimmermann, Susanne Ferschl, Matthias W. Birkwald, weiterer Abgeordneter und der Fraktion DIE LINKE. Drucksache 19/6792
- Emunds, B. and Schacher, U. (2012) Ausländische Pflegekräfte in Privathaushalten, Frankfurter Arbeitspapiere zur gesellschaftsethischen und sozialwissenschaftlichen Forschung des Oswald von Nell-Breuning Instituts für Wirtschafts-und Gesellschaftsethik der Philosophisch Theologischen Hochschule St. Georgen.
- Federal Statistical Office (2017) Pflegestatistik 2015, https://www.destatis.de/DE/Publikationen/Thematisch/Gesundheit/Pflege/PflegeDeutschlandergebnisse5224001159004.pdf?__blob=publicationFile
- Friberg, J.H., Arnholtz, J., Eldring, L., Hansen, N.W. and Thorarins, F. (2014) Nordic labour market institutions and new migrant workers: Polish migrants in Oslo, Copenhagen and Reykjavik, European Journal of Industrial Relations, 20, 1, 37-53.
- Gile, K.J., Beaudry, I.S., Handcock, M.S. and Ott, M.Q. (2018) Methods for inference from respondent-driven sampling data, Annual Review of Statistics and Its Application, 5, 1, 65-93.
- Heckathorn, D.D. (1997) Respondent-driven sampling: A new approach to the study of hidden populations, Social Problems, 44, 2, 174-199.
- Heckathorn, D.D. (2002) Respondent-driven sampling II: deriving valid population estimates from chain-referral samples of hidden populations, Social Problems, 49, 1, 11-34.
- Heckathorn, D.D. and Cameron, C.J. (2017) Network sampling: From snowball and multiplicity to respondent-driven sampling, Annual Review of Sociology, 43, 1, 101-119.
- Heckathorn, D.D. and Jeffri, J. (2001) Finding the beat: Using respondent-driven sampling to study jazz musicians, Poetics, 28, 4, 307-329.
- Heckathorn, D.D., Semaan, S., Broadhead, R.S. and Hughes, J.J. (2002) Extensions of respondent-driven sampling: A new approach to the study of injection drug users aged 18–25, AIDS and Behavior, 6, 1.
- Johnston, L.G., Whitehead, S., Simic-Lawson, M. and Kendall, C. (2010) Formative research to optimize respondent-driven sampling surveys among hard-to-reach populations in HIV behavioral and biological surveillance: lessons learned from four case studies, AIDS Care, 22, 6, 784-792.
- Karakayali, J. (2010) Die Regeln des Irregulären–Häusliche Pflege in Zeiten der Globalisierung Transnationale Sorgearbeit: Springer. pp. 151-169.
- Kniejska, P. (2016) Migrant Care Workers aus Polen in der häuslichen Pflege, Zwischen familiärer Nähe und beruflicher Distanz, Dortmund. Springer.
- Lee, S., T. Suzer-Gurtekin, J. Wagner, and R. Valliant (2017) Total survey error and respondent driven sampling: Focus on nonresponse and measurement errors in the recruitment process and the network size reports and implications for inferences, Journal of Official Statistics, 33, 335-366.
- Martiny, A. and Stolterfoht, B. (2013) Transparenzmängel, Betrug und Korruption im Bereich der Pflege und Betreuung. Schwachstellenanalyse von Transparency Deutschland Transparency International Deutschland e.V. Die Koalition gegen Korruption. https://www.transparency.de/fileadmin/Redaktion/Publikationen/2013/Pflegegrundsaetze_TransparencyDeutschland_2013.pdf
- Montealegre, J.R., Risser, J.M., Selwyn, B.J., McCurdy, S.A. and Sabin, K. (2013) Effectiveness of respondent driven sampling to recruit undocumented central American immigrant women in Houston, Texas for an HIV behavioral survey, AIDS and Behavior, 17, 2, 719-727.
- Salganik, M.J. (2006) Variance estimation, design effects, and sample size calculations for fespondent-driven sampling, Journal of Urban Health : Bulletin of the New York Academy of Medicine, 83, Suppl. 1, 98-112.
- Semaan, S., Santibanez, S., Garfein, R.S., Heckathorn, D.D. and Des Jarlais, D.C. (2009) Ethical and regulatory considerations in HIV prevention studies employing respondent-driven sampling, International Journal of Drug Policy, 20, 1, 14-27.
- WHO (2013) Introduction to HIV/AIDS and sexually transmitted infection surveillance Module 4: Introduction to respondent-driven sampling: Regional Office for the Eastern Mediterranean. https://apps.who.int/iris/bitstream/handle/10665/116864/EMRPUB_2013_EN_1539.pdf?sequence=1&isAllowed=y
- ZQP (2016) Pflegeversorgung – Grauer Arbeitsmarkt: Zentrum für Qualität in der Pflege. https://www.zqp.de/wp-content/uploads/Fachartikel_Grauer_Arbeitsmarkt.pdf
-
Keywords
calibration CATI coverage coverage bias cross-national surveys data linkage data quality European Social Survey experiment face-to-face face-to-face survey Facebook hard to reach populations incentives item nonresponse measurement measurement error mixed-mode surveys multitasking non-probability samples Nonresponse nonresponse bias nonresponse rates paradata PIAAC Probability sample probability samples QR codes rare populations response rate Satisficing social desirability Social media survey survey-taking climate survey data survey management survey methods Telephone survey telephone surveys total survey error unit nonresponse validity web survey Web surveys weighting
